Hipóteses De Escrita Tabela

Na prática de modelagem de dados e desenvolvimento de software, entender as hipóteses de escrita tabela é essencial para projetar sistemas eficientes e consistentes.
O que são e por que importam as hipóteses de escrita tabela
As hipóteses de escrita tabela são pressupostos sobre como as operações de INSERT, UPDATE e DELETE ocorrem em uma estrutura tabular dentro de um banco de dados relacional. Elas definem regras sobre quando e como uma linha pode ser alterada, influenciando diretamente a integridade dos dados, o bloqueio de registros e o desempenho de transações simultâneas. Sem um entendimento claro dessas hipóteses, aplicações podem sofrer com corrupção de informações, leituras inconsistentes ou gargalos de concorrência que comprometem a confiabilidade do sistema.
Do ponto de vista arquitetônico, estabelecer hipóteses de escrita tabela ajuda a alinhar a lógica de negócio com as características do banco de dados, seja ele otimizado para transações OLTP ou para análises OLAP. Cada tabela pode ter requisitos distintos, e reconhecer esses requisitos desde o início evita retrabalho custoso em fases posteriores do ciclo de vida do produto. Por isso, modeladores e desenvolvedores dedicam atenção especial a esse aspecto ao esboçar entidades e relacionamentos.
Tipos principais de hipóteses de escrita tabela
Uma das classificações mais úteis divide as hipóteses de escrita tabela em cenários de alta concorrência, baixa concorrência, escrita exclusiva e leitura otimizada. Em ambientes de alta concorrência, assume-se que múltiplas transações tentam modificar as mesmas linhas simultaneamente, exigindo mecanismos de bloqueio otimistas ou pessimistas para evitar lost updates e garantir serialização. Em contrapartida, em tabelas com baixa concorrência, pode-se adotar estratégias mais simples, como bloqueio de linha único, reduzindo overhead de gerenciamento de conflitos.
Já a hipótese de escrita exclusiva pressupõe que, em certos períodos, apenuma transação ou um lote de jobs terá acesso de modificação à tabela, o que permite trabalhar com locks mais agressivos e menos verificações de conflitos. Já a hipótese de leitura otimizada, comum em data warehouses, indica que a atividade de consulta será muito maior que a de escrita, possibilitando o uso de técnicas como snapshot isolation e replicação para consultas sem bloqueio. Identificar qual desses perfis se aproxima mais do seu caso de uso é um dos primeiros passos para aplicar as hipóteses de escrita tabela de forma acertada.
- Alta concorrência: múltiplas transações simultâneas exigem controle fino de isolamento.
- Baixa concorrência: menos necessidade de bloqueios complexos e controle otimista.
- Escrita exclusiva: períodos de manutenção ou jobs em lote com acesso exclusivo.
- Leitura otimizada: predominância de consultas com escritas pontuais e assíncronas.
Como as hipóteses de escrita tabela influenciam o isolamento transacional
O nível de isolamento configurado em uma transação está diretamente ligado às hipóteses de escrita tabela que você assume ao projetar o modelo. Em tabelas sujeitas a escrita intensiva, níveis mais rigorosos, como Serializable, podem ser necessários para evitar phantoms e inconsistências, mas isso pode reduzir a taxa de throughput por aumento de bloqueios e rollback. Por outro lado, em cenários de leitura pesada, um isolamento Read Committed ou Snapshot pode oferecer um equilíbrio saudável, mantendo consistência sem sacrificar performance.

A escolha do isolamento também impacta o comportamento de bloqueio: configurações mais restritivas aumentam a probabilidade de espera e deadlock, enquanto configurações mais leves exigem que as hipóteses de escrita tabela sejam alinhadas com a tolerância a leituras sujas ou não repetíveis. Avaliar cuidadosamente essa relação entre isolamento, concorrência e requisitos de negócio ajuda a evitar surpresas em produção e a dimensionar corretamente os recursos de banco de dados.
Ferramentas e práticas para validar hipóteses de escrita tabela
Testar as hipóteses de escrita tabela antes de colocar em produção é uma etapa crítica que pouca gente faz de forma estruturada. Uma abordagem eficaz envolve simulações de carga com diferentes perfis de acesso, uso de explain plans para entender planos de execução e monitoramento de locks, waits e tempdb sob cenários de pico. Bancos de dados modernos oferecem recursos como DMVs, eventos estendidos e métricas de wait type que permitem validar se as premissas iniciais estão se mantendo durante a vida útil da aplicação.
Além das ferramentas, práticas como revisão de código de acesso a dados, análise de padrões de SQL e documentação clara das regras de negócio ajudam a manter as hipóteses de escrita tabela alinhadas com a realidade. Quando uma tabela começa a se desviar do perfil esperado — por exemplo, crescimento inesperado de escritas em um cenário otimizado para leitura — é sinal de que as premissas devem ser revisadas e o modelo ajustado para evitar degradação de performance e riscos à integridade.
Erros comuns e como evitá-los ao lidar com hipóteses de escrita tabela
Um dos erros mais frequentes é subestimar a variabilidade da carga de escrita ao longo do tempo. Uma tabela que nasce como leitura otimizada pode, com crescimento de usuário ou novas funcionalidades, virar um alvo de concorrência alta, exigindo uma revisão imediata das hipóteses de escrita tabela e, consequentemente, dos índices, chaves e níveis de isolamento. Ignorar essa evolução gera retrabalho custoso e, muitas vezes, exige reestruturação de aplicações inteiras para reaproveitar o esforço inicial.
Outro problema comum é aplicar as mesmas hipóteses de escrita tabela a todos os módulos de um mesmo banco, sem considerar as particularidades de cada entidade. Uma tabela de logs, por exemplo, pode tolerar bloqueios mais leves e priorizar inserções rápidas, enquanto uma tabela financeira exige rigor absoluto em relação a transações e consistência. Portanto, estudar cada caso com profundidade, ajustar configurações de banco e documentar as premissas ajuda a construir soluções escaláveis, seguras e alinhadas com as expectativas dos stakeholders.
Conclusão
Dominar as hipóteses de escrita tabela é um passo decisivo para projetos de banco de dados bem-sucedidos, pois conecta diretamente a modelagem teórica com as condições reais de operação. Ao antecipar padrões de acesso, configurar isolamentos adequados e validar cenários com testes práticos, você reduz riscos, ganha performance e entrega sistemas mais resilientes. Trate essas hipóteses como uma bússola que guia decisões de projeto, revisite-as periodicamente e ajuste conforme a evolução do produto.
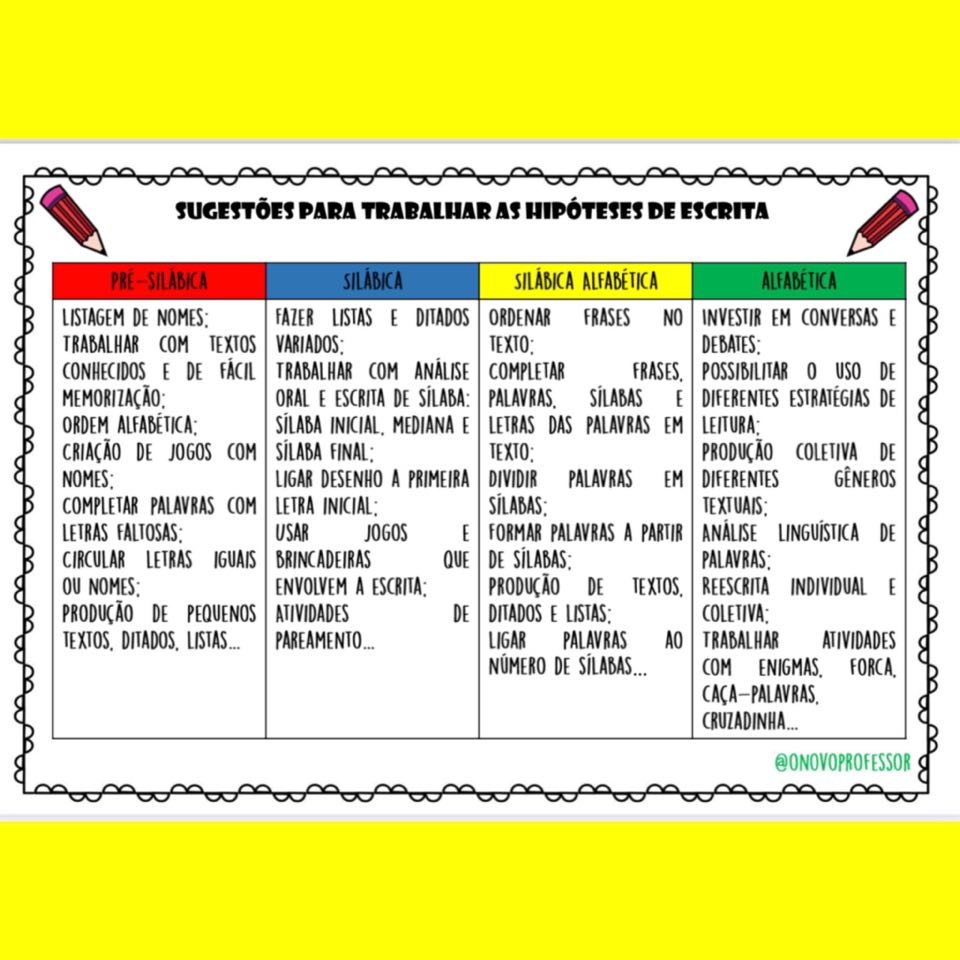
Resumão das fases da escrita
Neste vídeo apresento um resumão das fases da escrita.
